R es una herramienta excelente de “Social Network Analysis” para twitter, permite trabajar con búsquedas, perfiles, construir grafos, etc.. Una herramienta que descubrí el año pasado en el curso de SNA, y que estoy profundizando ahora.
Las posibiliades de R son muy amplias y hay numerosos tutoriales por la red. En este caso he querido vaciar la nube de tags de mis últimos 2000 twitts. El resultado, después de cierto trabajo de limpieza de algunos términos (por ejemplo adverbios, etc…) es el siguiente.
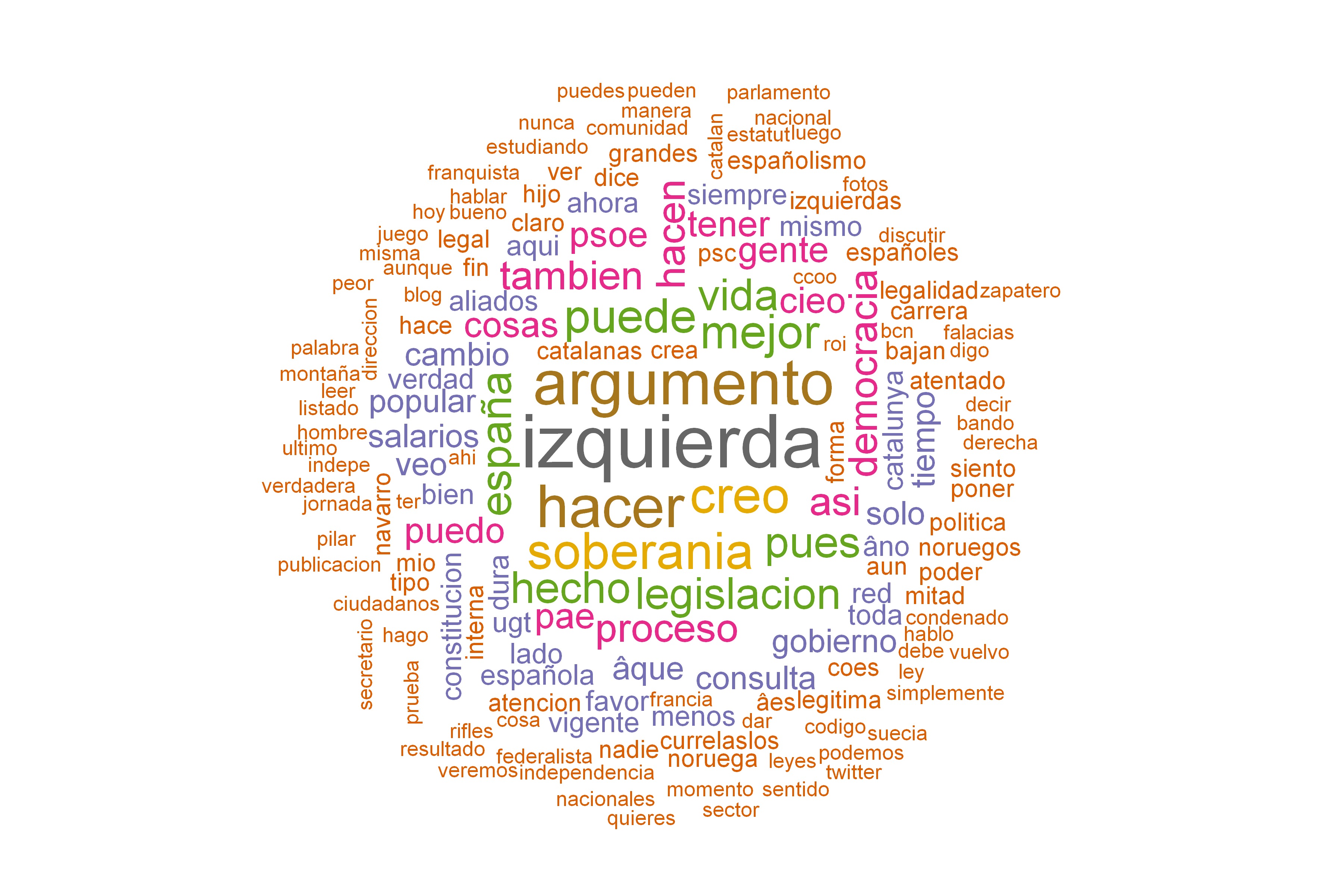
Las nubes de tags son una manera gráfica de ver que palabras se han utilizado más en la elaboración de un texto o en un discurso, o en este caso en twitter. Muestra más el metalenguaje y las minúsculas que hay detrás de quien elabora el texto, que el contenido del mismo.
Vaciando mi nube de tags
En mi caso yo pensaba, por ejemplo, por mi perfil más independentista que estos temas serían los más relevantes, y en cambio están a un tercer nivel. Quien lidera es el concepto de “izquierda” seguido por “argumento” y “hacer”. Casi parezco un activista del postureo progre con estas palabras clave, “pensar y actuar desde la izquierda”, podría ser el lema de mis metatags.
En un tercer nivel aparece el término “soberanía” (ahí está mi aspecto “indepe”) y “creo”, no me suponía tan “humilde”. Lo curioso es que mi aspecto de crítica al PSC y al PSOE está en el enésimo lugar, en el conjunto de 50 palabras más utilizadas pero ahí, al fondo. Lo cuál indica que mis críticas no son tan frecuentes como algunos creen (yo mismo).
Curiosamente lo que esperaba en un principio, que mis tags estarían dominados en un primer nivel por el debate soberanista, no es así, sigo, incluso en un momento como este, hablando de temas asociados al eje social y mi crítica a la dirección del PSC y del PSOE es un tema muy secundario entre los temas de los que hablo en twitter.
La parte técnica, ¿cómo conseguirlo?
El Script que he utilizado es una versión mejorada de este. Se ha de utilizar en R, o R-Studio (con el R instalado, claro). El Script está lo suficientemente comentado para aclarar que hace casi cada línea de código y los problemas a los que te puedes enfrentar. Al ejecutar el script en R nos preguntará:
- El nombre del usuario del que queremos extraer los datos (variable, user)
- El número de twitts en los que queremos profundizar (variable, TweetNumber), cuantos más, más tardará el script y más posibilidades hay que alcancemos el límite que nos permite twitter a nuestra API funcionar, hay un límite máximo de 3.200.
Antes de poder ejecutarlo tenemos que conseguir un archivo .RData (y lo pondremos en el script, ver anotación).
- Nombre del archivo .RData donde tendremos nuestra validación en la API de twitter. Esta es la parte más complicada, la solución está en los comentarios. Agradezco a Carlos Guadian, su orientación en esta parte.
Se puede grabar el archivo como un script de R, o bien copiar y pegar directamente (con la selección de nuestras variables) en la consola de R.
Recomendación a usuarios de R-Studio en Windows: Cuando grabéis el Script seleccionar hacerlo con codificación y esta sea Windows-1252, sino los elementos que transforman los carácteres especiales del castellano (acentos, ñ, etc..) en su forma final, no funcionarán.
Script nubetagsusuario.R
############# Objetivo del programa ###############################
## Nombre: Nube de palabras de los twitts de un usuario.
## Objetivo: Función que intenta hacer nube de lo que dice un usuario en twitter
## Descripción: Introduzco el nombre de un usuario de twitter
## y consigo una imagen con la nube de tags
## de los últimos N twitts realizados.
## Output: Una imagen con la nube de tags
##
## Sistema en el que está testeado:
## R-Studio con R 3.0.2 funcionando bajo Windows-XP SP3
## Válido para la API de Twitter 1.1
###################################################################
############## Definición de variables ###########################
## user es una "String"
## Es el nombre del usuario del que quiero buscar su nube de tags
user = readline("¿Cuál es el nombre del usuario? ")
## TweetNumber es un "Number"
## Es el número de twitts en los que quiero ahondar
TweetNumber = readline("Cuantos tweets quieres analizar? ")
TweetNumber = as.numeric(unlist(strsplit(TweetNumber, ",")))
palabrasstop = readline("Define las palabras que no quieres que aparezcan (separadas por espacios y en minúsculas) ")
palabrasstop = unlist(strsplit(palabrasstop, split=" "))
############ Preámbulos necesarios para que funcione ##############
##
## Librerías que son necesarias para funcionar en R
## ¡Recuerda instalarlas antes!
#########################################################
library(twitteR)
library(tm)
library(wordcloud)
library(RColorBrewer)
## ATENCIÓN USUARIOS DE WINDOWS:
## Esta parte es necesaria para los usuarios de Windows para
## superar problemas de permisos
library(RCurl)
options(RCurlOptions = list(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")))
u = "https://raw.github.com/tonybreyal/Blog-Reference-Functions/master/R/bingSearchXScraper/bingSearchXScraper."
x = getURL(u, cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl"))
## Autentificación con twitter, tienes que tener tu propio fichero .RData acreditado
load("rcredenciales.RData") ## El tener tu propio .RData autentificado es una parte compleja
registerTwitterOAuth(tw)
##################### Aclaración para conseguir tu .RData ######################
## Una explicación de cómo obtenerlo:
##
## 1.- Necesitas darte de alta como desarrollador
## en dev.twitter.com
## 2.- Da de alta una app y consigue tu consumer key
## y tu secret ke y.
## 3.- Sigue los primeros pasos hasta conseguir el .RData:
## http://aaronccrowley.wordpress.com/2013/05/27/extracting-data-from-twitter-with-r/
##
## Alerta: si eres usuario de windows en el script citado
## tendrás que incluir las líneas 42 a 50 del actual Script al inicio del Script
## indicado en la web
####################################################
##################### Inicio el propio programa en sí mismo #######
##### Comenzamos descargándonos en nuestro Workspace los twitts del usuario
mach_tweets = userTimeline(user, n=TweetNumber)
###### Extraigo el texto de los tweets y hago una Lista
mach_text = sapply(mach_tweets, function(x) x$getText())
#####################################################
## Limpieza del texto de carácteres incompatibles o contenidos
## sin valor semántico (preposiciones, etc..)
##
## R gestiona mal los carácteres especiales del castellano y catalá
## Estos scripts sustituyen carácteres en castellano / catalán.
## Si el script.R no está grabado con el Encoding adecuado
## se ha de ejecutar el código en la consola a trozos a partir de
## aquí
## Por ejemplo: La codificación del script ha de ser Windows para usuarios Windows
## y no UTF-8 o algún ISO
########################################################3
########## Establezco el sistema local del idioma (solo para usuarios Windows)
Sys.setlocale("LC_CTYPE", "spanish")
## Función no definida (para evitar problemas de ejecución
## he preferido ejecutar una por una las substituciones)
##
## Transforma una Lista() en otra Lista()
## Objetivo: Sustituye los carácteres mal descargados por
## carácteres latinos que los scripts puedan leer sin problemas
mach_text = tolower(mach_text)
mach_text = gsub("ã¡", "a", mach_text)
mach_text = gsub("ã©", "e", mach_text)
mach_text = gsub("ã³", "o", mach_text)
mach_text = gsub("ãº", "u", mach_text)
mach_text = gsub("ã±", "ñ", mach_text)
mach_text = gsub("ã¨", "e", mach_text)
mach_text = gsub("ã²", "o", mach_text)
mach_text = gsub("ã", "i", mach_text)
## Se define la función clean.text
## Transforma una Lista() en otra Lista()
## Objetivo: Filtra palabras (evita URL, @usuarios, etc...)
##
clean.text = function(x)
{
# tolower
x = tolower(x)
# remove rt
x = gsub("rt", "", x)
# remove at
x = gsub("@\\w+", "", x)
# remove punctuation
x = gsub("[[:punct:]]", "", x)
# remove numbers
x = gsub("[[:digit:]]", "", x)
# remove links http
x = gsub("http\\w+", "", x)
# remove tabs
x = gsub("[ |\t]{2,}", "", x)
# remove blank spaces at the beginning
x = gsub("^ ", "", x)
# remove blank spaces at the end
x = gsub(" $", "", x)
return(x)
}
mach_text = clean.text(mach_text)
mach_text = gsub("mas", "", mach_text) ## elimino la palabra "mas"
############################################
## Transformamos la lista de textos en vectores y
## luego en una matriz
##############################################3
## Creamos un Corpus vectorial con los twitts
## Transformamos una Lista () en un Corpus de vectores
mach_corpus = Corpus(VectorSource(mach_text)
)
## Creamos una matriz, limpiamos los elementos que nos sobran (los artículos, etc..)
## Transformamos un Corpus en una matriz
# create document term matrix applying some transformations
tdm = TermDocumentMatrix(mach_corpus,
control = list(removePunctuation = TRUE,
stopwords = c(stopwords("spanish"), stopwords("catalan"), "@", palabrasstop),
removeNumbers = TRUE, tolower = TRUE))
# define tdm as matrix
m = as.matrix(tdm)
##################################################################
######### Contamos la frecuencia de las palabras utilizadas #######
##############################################################3
# get word counts in decreasing order
word_freqs = sort(rowSums(m), decreasing=TRUE)
# create a data frame with words and their frequencies
dm = data.frame(word=names(word_freqs), freq=word_freqs)
# plot wordcloud
wordcloud(dm$word, dm$freq, random.order=FALSE, max.words=25, colors=brewer.pal(8, "Dark2"))
########## Guardo un archivo de texto con las palabras más usadas
## y su frecuencia
## Puede ser utilizado después en otras herramientas de análisis, y
## abierto con Open Office, Excel, etc..
#############################################################3
## Construyo un nombre para el fichero txt basado en el usuario
fichero.txt = paste(user,".txt")
fichero.txt = gsub(" ", "", fichero.txt)
## Ejecuto el write que crea el fichero texto, este fichero
## tendrá tantas filas como palabras detectadas en los twitts
## y separado por un espacio el número de repeticiones
## La importación desde Excel o Open Office o Drive es trivial
## recordando que la separación es de un espacio
## Podemos forzar otro tipo de separaciones, por ejemplo ";"
## write.table(dm, fichero.txt, row.names = FALSE, sep = ";")
write.table(dm, fichero.txt, row.names = FALSE)
######### Creo una nube de tags #####################
## Construyo una paleta de colores
degradado = function (color1, color2, degradados)
{
library(grDevices)
palete = colorRampPalette(c(color1, color2))
palete (degradados)
}
mipaleta = degradado ("#DD0000", "#FFFF00", 25)
## transformo la lista de twitts en una forma más manejable
tweetsdf = twListToDF(mach_tweets)
## creo la función last para sacar la última entrada
## y su fecha
last = function(x) { tail(x, n = 1) }
## Dibujo la nube de tags
par(bg = "black", mar=c(0,0,0,0)) ## Establezco un fondo negro
wordcloud(dm$word, dm$freq, random.order=FALSE, max.words=100, colors=mipaleta) ## construye la nube de tags
legend("bottom", title=paste("Nube de tags @",user, " ", TweetNumber, " tweets analizados", sep=""), legend=paste("Tweets desde ",last(tweetsdf$created), " hasta ",tweetsdf$created[1]), text.col="#FFFFFF", bg="#333333B2", inset=0)
Más código
¿Qué aporta este script?
Hay diversos tutoriales de Twitter Data Mining con R, pero muchos de los scripts que presentan carecen de la capacidad de construir programas y funciones reproducibles (o sabes bastante de R o personalizarlo se vuelve algo difícil), no suelen describir lo que hace cada parte (¿esta función me transforma una “string” en un número? ¿construye una matriz, pero a partir de qué… un vector, una lista?) y algunos tienen problemas de estructuración además no suelen contener comentarios para usuarios novatos (como un servidor).
Además muchos de estos tutoriales no contienen las soluciones a posibles problemas. Por ejemplo, los usuarios de windows siempre han de incluir el siguiente código para realizar autentificaciones a la API de twitter:
library(RCurl)
options(RCurlOptions = list(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")))
u = "https://raw.github.com/tonybreyal/Blog-Reference-Functions/master/R/bingSearchXScraper/bingSearchXScraper."
x = getURL(u, cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl"))
Por otro lado, los carácteres especiales del castellano (o el catalán), como los acentos, las “ñ” o las “ç” son mal gestionadas en los scripts que intentan hacer nubes de palabras. He mejorado esos problemas de forma parcial (seguramente haya mejores soluciones), y he indicado donde para que otro desarrollador pueda encontrar soluciones más avanzadas.
Estos problemas y otros menores los he ido descubriendo y los he incluido en un script completo, más comprensivo, que por ejemplo, el script original en el que está basado.
Más artículos relacionados
 El riesgo de creerse las métricas del 2.0 sin revisarlas antes
El riesgo de creerse las métricas del 2.0 sin revisarlas antes Creación con R de dendogramas semánticos y clústers de conversaciones en twitter
Creación con R de dendogramas semánticos y clústers de conversaciones en twitter Analizar con cierta profundidad la actividad de un #hashtag de twitter con R
Analizar con cierta profundidad la actividad de un #hashtag de twitter con R Análisis del debate en twitter de #sumantxbcn y #primariesobertesbcn: Las primarias interesan a los activistas y el público interno, aún no al externo.
Análisis del debate en twitter de #sumantxbcn y #primariesobertesbcn: Las primarias interesan a los activistas y el público interno, aún no al externo.


Buenas:
He introducido el código y el resultado es casi satisfactorio, excepto porque la frecuencia de las palabras (la más repetida tiene una frecuencia de 7 apariciones) me hace sospechar que no está cogiendo todos los tuits que le pido. ¿Cómo podría resolver eso?
Otra cosa: ¿habría alguna posibilidad de suprimir palabras que no sean ni preposiciones ni artículos pero que no aporten nada al gráfico?
Muchas gracias.
VultureCt:
Para saber si coge todos los twitts que le pides haz la siguiente exportación:
Te dará un fichero .txt que puedes abrir desde el propio R-Studio, o bien meter la siguiente orden:
y te devolverá algo del estilo
char[1:N]
o bien
que te enumerará el número de tweets que te has descargado “en bruto” antes de transformarlo en mach_text
Siendo N el número de líneas que tiene (y por tanto los twitts que ha hecho)
Si te lees la documentación del paquete twitteR para R, http://cran.r-project.org/web/packages/twitteR/twitteR.pdf verás una cosa:
Por “default”, hay un variable que puedes modificar al tomar los twitts y es la “includeRts”, de serie es “falso”. Si esto lo configuras así, tendrás:
includeRts If FALSE any native retweets (not old style RT retweets) will be stripped from
the results
Lo cuál quiere decir que cuando haces la búsqueda de N, buscará las últimas N entradas del TL del usuario, sean o no RT, y luego con el includeRts = FALSE, ocurrirá que los separa de la selección.
La supresión de palabras que no son artículos puedes hacerlo de la siguiente manera, incluye líneas nuevas a partir de la 42 y antes de la 44:
######################################################### ## Introducir después enre la línea 42 y 44 del script de ## creación de nubes de tags ## ## Función: Eliminar palabras concretas de la nube de tags ## Limpio mach_text de una serie de palabras que no ## quiero que aparezcan en mi nube de tags, por ejemplo ## si el usuario analizado siempre utiliza "LOL" al final ## del texto. ## ## Primero identificamos que palabras quiero eliminar y pondría ## tantas líneas como palabras quiero eliminar, en este ejemplo ## hay 3 palabras "palabraquequieroeliminar1, 2 y 3. ## ######################################################### mach_text = gsub("palabraquequieroeliminar1", "", mach_text) mach_text = gsub("palabraquequieroeliminar2", "", mach_text) mach_text = gsub("palabraquequieroeliminar3", "", mach_text)Y así con todas las que tú deseas eliminar (recuerda en minúscula, ya que el script clean.txt lo ha puesto todo en minúsculas).
Otra forma más rápida.. es la siguiente, el script te genera un fichero texto que recoge todas las palabras más usuadas que lo guarda en tu directorio de trabajo que es “nombreusuario.txt”. Puedes abrirlo y eliminarlas manualmente, e importarlo nuevamente a R, o bien llevarlo a http://www.wordle.net/advanced y pegar lo que has obtenido y limpiado.
Hola,
Mil gracias por este código funciona perfecto, sin embargo, he notado que Twitter me denegó seguir usando la apliación que he creado para enlazarme con R, esto es ilegal?
El problema puede venir en que no hayas guardado la acreditación de twitter en un fichero R que puedas recuperar fácilmente, aquí lo explican:
http://aaronccrowley.wordpress.com/2013/05/27/extracting-data-from-twitter-with-r/
Por el momento la API de twitter permite la descarga de estos datos sin problemas, no es nada “ilegal”.
Hola, buenos días :) me gustaria saber como puedo realizar una Nube de palabras despúes de haber hallado las asociaciones entre palabras
Muchas gracias por este magnífico tutorial. Como bien dices, es posible encontrar otros buenos ejemplos, pero el tuyo tiene la inmensa virtud de explicar cada paso. Y ya se sabe, más vale enseñar a pescar que regalar pescado. Gracias de nuevo. Voy a explorar el resto de la web.
Muy interesante. Una forma más de cómo extraer información de Twitter. Ahora bien. ¿No te has topado nunca con tutis que contengan emojis que aparece como \xed\xa0\xbd\xed\xb5\x96 (creo que corresponde a un reloj)? ¿Cómo los limpias?